কুবারনেটসে পাইস্পার্ক মাইক্রোসার্ভিস মোতায়েন: ইলুমের সাথে ডেটা লেকগুলিতে বিপ্লব ঘটানো।

ইলাম উত্সাহী এবং পাইথন ভক্তদের শুভেচ্ছা! আমরা একটি নতুন, অধীর আগ্রহে প্রত্যাশিত বৈশিষ্ট্য উন্মোচন করতে পেরে রোমাঞ্চিত যা আপনার ডেটা সায়েন্স যাত্রাকে শক্তিশালী করার জন্য সেট করা হয়েছে - ইলুমে সম্পূর্ণ পাইথন সমর্থন। ডেটা ওয়ার্ল্ডে যারা আছেন তাদের জন্য, পাইথন এবং অ্যাপাচি স্পার্ক দীর্ঘদিন ধরে একটি আইকনিক জুটি, নির্বিঘ্নে বিপুল পরিমাণে ডেটা এবং জটিল গণনা পরিচালনা করে। এবং এখন, ইলমের সর্বশেষ আপগ্রেডের সাথে, আপনি আপনার প্রিয় ডেটা লেক পরিবেশের ভিতরে পাইথনের শক্তি ব্যবহার করতে পারেন।
এই ব্লগ পোস্টটি এই বৈশিষ্ট্যটি অন্বেষণ করার জন্য আপনার গাইডেড ট্যুর। আমরা পাইথনে লেখা একটি সাধারণ অ্যাপাচি স্পার্ক কাজ দিয়ে জিনিসগুলি শুরু করব, এটি ইলুমে চালাব এবং তারপরে আরও গভীরভাবে ডুব দেব। আমরা একটি ইন্টারেক্টিভ মোড সমর্থন করার জন্য প্রাথমিক কোডটি রূপান্তর করব, আপনাকে ইলমের এপিআইয়ের মাধ্যমে স্পার্ক জবে সরাসরি অ্যাক্সেস সরবরাহ করব। এই যাত্রার শেষে, আপনার কাছে একটি পাইথন-ভিত্তিক মাইক্রোসার্ভিস থাকবে যা এপিআই কলগুলিতে সাড়া দেবে, সমস্ত ইলমে মসৃণভাবে চলছে।
সুতরাং, আপনি পাইথন এবং ইলাম সঙ্গে আপনার তথ্য খেলা উন্নত করতে প্রস্তুত? চলুন শুরু করা যাক।
সমস্ত উদাহরণ আমাদের এ পাওয়া যায় GitHub repository .
ধাপ 1: পাইথনে একটি সাধারণ অ্যাপাচি স্পার্ক কাজ লেখা।
ইলুমের সাথে আমাদের পাইথন যাত্রা শুরু করার আগে, আমাদের পরিবেশটি ভালভাবে সজ্জিত রয়েছে তা নিশ্চিত করতে হবে। স্পার্কের কাজ চালানোর জন্য আপনার ইলাম এবং পাইস্পার্ক ইনস্টল করা দরকার। আপনি পাইস্পার্ক সেট আপ করতে পাইথন প্যাকেজ ইনস্টলার পিপ ব্যবহার করতে পারেন। নিশ্চিত হয়ে নিন যে আপনি পাইথন ব্যবহার করছেন >=3.9।
পিপ ইনস্টল পাইস্পার্ক ইলম সেট আপ এবং অ্যাক্সেস করার জন্য, দয়া করে প্রদত্ত নির্দেশিকাগুলি অনুসরণ করুন এখানে .
1.1 স্পার্কপাই উদাহরণ।
এখন, আসুন আমাদের স্পার্ক কাজটি লেখার মধ্যে ডুব দিন। আমরা স্পার্কপাই এর একটি সহজ উদাহরণ দিয়ে শুরু করব
Import sys
এলোমেলো আমদানি থেকে এলোমেলো
অপারেটর থেকে আমদানি যোগ করুন
pyspark.sql থেকে স্পার্কসেশন আমদানি করুন
যদি __name__ == "__main__":
স্পার্ক = স্পার্কসেশন \
.বিল্ডার \
.appName("PythonPi") \
.getOrCreate()
পার্টিশন = int(sys.argv[1]) যদি len(sys.argv) > অন্য 1 2
n = 100000* পার্টিশন
def f(_: int) -> float:
x = random() * 2 - 1
y = random() * 2 - 1
রিটার্ন 1 যদি এক্স ** 2 + ওয়াই ** 2 < = 1 অন্য 0
গণনা = স্পার্ক.স্পার্ককনটেক্সট.সমান্তরালকরণ (পরিসীমা (1, এন + 1), পার্টিশন).map(f).reduce(add)
মুদ্রণ ("পাই প্রায় %f"% (4.0 * গণনা / এন))
স্পার্ক.স্টপ () এই স্ক্রিপ্টটি এভাবে সংরক্ষণ করুন ilum_python_simple.py
আমাদের স্পার্কের কাজ প্রস্তুত হওয়ার সাথে সাথে এটি ইলুমে চালানোর সময় এসেছে। ইলাম ইউআই ব্যবহার করে বা রেস্ট এপিআইয়ের মাধ্যমে চাকরি জমা দেওয়ার ক্ষমতা সরবরাহ করে।
আসুন ইউআই দিয়ে শুরু করা যাক একক কাজের বৈশিষ্ট্য।
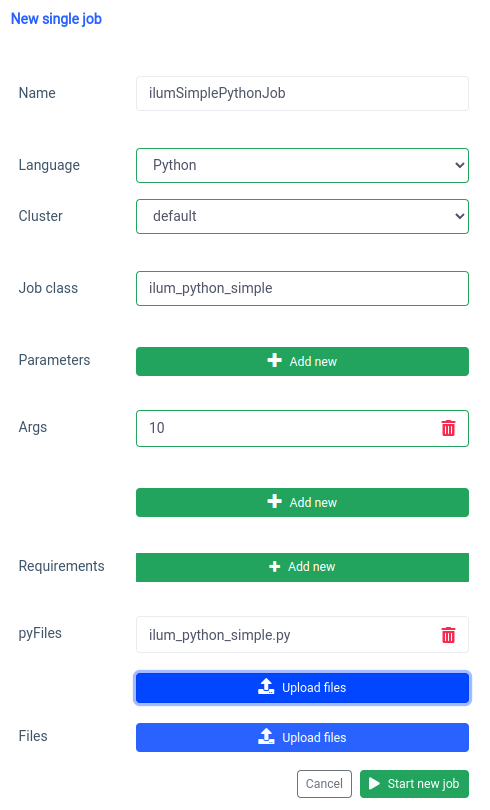
আমরা একই জিনিস সঙ্গে অর্জন করতে পারেন এপিআই , তবে প্রথমে, আমাদের পোর্ট ফরোয়ার্ডের সাথে আইএলএম-কোর এপিআই প্রকাশ করতে হবে।
- কুবেক্টল পোর্ট-ফরোয়ার্ড এসভিসি / আইএলইউএম-কোর 9888: 9888 উন্মুক্ত পোর্টের সাহায্যে আমরা একটি এপিআই কল করতে পারি।
কার্ল -এক্স পোস্ট 'লোকালহোস্ট: 9888 / এপিআই / ভি 1 / জব / সাবমিট' \
--ফর্ম 'name="ilumSimplePythonJob"' \
--ফর্ম 'ক্লাস্টারনাম="ডিফল্ট"' \
--ফর্ম 'জবক্লাস = "ilum_python_simple"' \
--ফর্ম 'আর্গস = "10"' \
--ফর্ম 'pyFiles=@"/path/to/ilum_python_simple.py"' \
--ফর্ম 'ভাষা="পাইথন"' এপিআই কল
ফলে আমরা সৃষ্ট কাজের আইডি পাব।
{"jobId":"20230724-1154-m78f3gmlo5j"} ফলাফল
কাজের লগগুলি পরীক্ষা করতে আমরা একটি এপিআই কল করতে পারি
কার্ল লোকালহোস্ট:9888 / এপিআই / ভি 1 / জব / 20230724-1154-এম 78 এফ 3 জিএমএলও 5 জে / লগ এপিআই কল
আর এটুকুই! আপনি ইলুমে একটি সাধারণ পাইথন স্পার্ক কাজ লিখেছেন এবং চালিয়েছেন। আসুন আরও কিছুটা উন্নত উদাহরণ দেখি যার জন্য অতিরিক্ত পাইথন লাইব্রেরি প্রয়োজন।
1.2 অসাড় সঙ্গে কাজের উদাহরণ।
এই বিভাগে, আমরা পাইথনে লেখা একটি স্পার্ক কাজের একটি ব্যবহারিক উদাহরণ নিয়ে যাব। এই কাজের মধ্যে একটি ডেটাসেট পড়া, এটি প্রক্রিয়াজাতকরণ, এটিতে একটি মেশিন লার্নিং মডেলকে প্রশিক্ষণ দেওয়া এবং ভবিষ্যদ্বাণীগুলি সংরক্ষণ করা জড়িত। আমরা একটি ব্যবহার করতে যাচ্ছি Tel-churn.csv ফাইল, যা আপনি আমাদের খুঁজে পেতে পারেন GitHub repository . জিনিসগুলি সহজ করার জন্য, আমরা এই ফাইলটি মিনিওর বিল্ড-ইন ইনস্ট্যান্সে ইলুম-ফাইলস নামে একটি বালতিতে আপলোড করেছি, যা ইলুম উদাহরণ থেকে স্বয়ংক্রিয়ভাবে অ্যাক্সেসযোগ্য। এর অর্থ আপনাকে এই উদাহরণের জন্য কোনও অ্যাক্সেস কনফিগার করার বিষয়ে চিন্তা করতে হবে না - ইলাম এটি কভার করেছে। তবে, আপনি যদি কখনও অন্য বালতি থেকে ডেটা আনতে চান বা নিজের প্রকল্পগুলিতে অ্যামাজন এস 3 ব্যবহার করতে চান তবে আপনাকে সেই অনুযায়ী অ্যাক্সেসগুলি কনফিগার করতে হবে।
এখন যেহেতু আমরা আমাদের ডেটা প্রস্তুত করেছি, আসুন পাইথনে আমাদের স্পার্ক কাজটি লেখার সাথে শুরু করা যাক। এখানে সম্পূর্ণ কোড উদাহরণ:
pyspark.sql থেকে স্পার্কসেশন আমদানি করুন
pyspark.ml আমদানি পাইপলাইন থেকে
pyspark.ml.feature আমদানি StringIndexer, VectorAssembler থেকে
pyspark.ml.classification আমদানি থেকে লজিস্টিক রিগ্রেশন
যদি __name__ == "__main__":
স্পার্ক = স্পার্কসেশন \
.বিল্ডার \
.appName ("IlumAdvancedPythonExample") \
.getOrCreate()
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True)
categoricalColumns = ['লিঙ্গ', 'অংশীদার', 'নির্ভরশীল', 'ফোন পরিষেবা', 'মাল্টিপললাইন', 'ইন্টারনেট সার্ভিস',
'অনলাইনসিকিউরিটি', 'অনলাইনব্যাকআপ', 'ডিভাইসপ্রোটেকশন', 'টেকসাপোর্ট', 'স্ট্রিমিংটিভি',
'স্ট্রিমিংমুভিজ', 'কন্ট্রাক্ট', 'পেপারলেস বিলিং', 'পেমেন্ট মেথড']
পর্যায় = []
ক্যাটাগরিকাল কলামগুলিতে ক্যাটাগরিকাল কলের জন্য:
stringIndexer = StringIndexer (inputCol=categoricalCol, outputCol=categoricalCol + "index")
পর্যায় += [stringIndexer]
label_stringIdx = StringIndexer (inputCol="Churn", outputCol="label")
পর্যায় += [label_stringIdx]
সংখ্যাসূচক = ['সিনিয়র সিটিজেন', 'মেয়াদ', 'মাসিক চার্জ']
অ্যাসেম্বলারইনপুটস = [সি + "সূচক" শ্রেণীবদ্ধ কলামগুলিতে সি এর জন্য] + সংখ্যাসূচক
অ্যাসেম্বলার = ভেক্টরঅ্যাসেম্বলার (inputCols=assemblerInputs, outputCol="features")
পর্যায় += [অ্যাসেম্বলার]
পাইপলাইন = পাইপলাইন (পর্যায় = পর্যায়)
পাইপলাইনমডেল = পাইপলাইন.ফিট (ডিএফ)
ডিএফ = পাইপলাইনমডেল.ট্রান্সফর্ম (ডিএফ)
ট্রেন, পরীক্ষা = df.randomSplit([0.7, 0.3], বীজ = 42)
lr = LogisticRegression (featuresCol="features", labelCol="label", maxIter=10)
lrModel = lr.fit(ট্রেন)
ভবিষ্যদ্বাণী = lrModel.transform(test)
predictions.select("customerID", "label", "prediction").show(5)
ভবিষ্যদ্বাণী.সিলেক্ট ("গ্রাহকআইডি", "লেবেল", "ভবিষ্যদ্বাণী").রাইট.অপশন ("শিরোনাম", "সত্য") \
.csv('s3a://ilum-files/predictions')
স্পার্ক.স্টপ () আসুন কোডটিতে ডুব দেওয়া যাক:
pyspark.sql থেকে স্পার্কসেশন আমদানি করুন
pyspark.ml আমদানি পাইপলাইন থেকে
pyspark.ml.feature আমদানি StringIndexer, VectorAssembler থেকে
pyspark.ml.classification আমদানি থেকে লজিস্টিক রিগ্রেশন এখানে, আমরা একটি স্পার্ক সেশন তৈরি করতে, একটি মেশিন লার্নিং পাইপলাইন তৈরি করতে, ডেটা প্রিপ্রসেস করতে এবং একটি লজিস্টিক রিগ্রেশন মডেল চালানোর জন্য প্রয়োজনীয় পাইস্পার্ক মডিউলগুলি আমদানি করছি।
স্পার্ক = স্পার্কসেশন \
.বিল্ডার \
.appName ("IlumAdvancedPythonExample") \
.getOrCreate() আমরা একটি আরম্ভ করি স্পার্কসেশন , যা স্পার্কের কোনও কার্যকারিতার এন্ট্রি পয়েন্ট। এখানেই আমরা অ্যাপ্লিকেশনটির নাম সেট করি যা স্পার্ক ওয়েব ইউআইতে উপস্থিত হবে।
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True) আমরা একটি মিনিও বালতিতে সঞ্চিত একটি সিএসভি ফাইল পড়ছি। ঐ শিরোনাম = সত্য বিকল্পটি স্পার্ককে সিএসভি ফাইলের প্রথম সারিটি শিরোনাম হিসাবে ব্যবহার করতে বলে, যখন inferSchema=True স্পার্ক স্বয়ংক্রিয়ভাবে প্রতিটি কলামের ডেটা টাইপ নির্ধারণ করে।
categoricalColumns = ['লিঙ্গ', 'অংশীদার', 'নির্ভরশীল', 'ফোন পরিষেবা', 'মাল্টিপললাইন', 'ইন্টারনেট সার্ভিস',
'অনলাইনসিকিউরিটি', 'অনলাইনব্যাকআপ', 'ডিভাইসপ্রোটেকশন', 'টেকসাপোর্ট', 'স্ট্রিমিংটিভি',
'স্ট্রিমিংমুভিজ', 'কন্ট্রাক্ট', 'পেপারলেস বিলিং', 'পেমেন্ট মেথড'] আমরা আমাদের ডেটাতে কলামগুলি নির্দিষ্ট করি যা শ্রেণিবদ্ধ। এগুলি পরে স্ট্রিংইনডেক্সার ব্যবহার করে রূপান্তরিত হবে।
পর্যায় = []
ক্যাটাগরিকাল কলামগুলিতে ক্যাটাগরিকাল কলের জন্য:
stringIndexer = StringIndexer (inputCol=categoricalCol, outputCol=categoricalCol + "index")
পর্যায় += [stringIndexer] এখানে, আমরা আমাদের শ্রেণীবদ্ধ কলামগুলির তালিকার উপর পুনরাবৃত্তি করছি এবং প্রতিটিটির জন্য একটি স্ট্রিংইনডেক্সার তৈরি করছি। স্ট্রিংইনডেক্সারগুলি সূচকগুলির একটি কলামে শ্রেণিবদ্ধ স্ট্রিং কলামগুলি এনকোড করে। রূপান্তরিত সূচী কলামটি "সূচী" এর সাথে যুক্ত মূল কলামের নাম হিসাবে নামকরণ করা হবে।
সংখ্যাসূচক = ['সিনিয়র সিটিজেন', 'মেয়াদ', 'মাসিক চার্জ']
অ্যাসেম্বলারইনপুটস = [সি + "সূচক" শ্রেণীবদ্ধ কলামগুলিতে সি এর জন্য] + সংখ্যাসূচক
অ্যাসেম্বলার = ভেক্টরঅ্যাসেম্বলার (inputCols=assemblerInputs, outputCol="features")
পর্যায় += [অ্যাসেম্বলার] এখানে আমরা আমাদের মেশিন লার্নিং মডেলের জন্য ডেটা প্রস্তুত করি। আমরা একটি ভেক্টরঅ্যাসেম্বলার তৈরি করি যা আমাদের সমস্ত বৈশিষ্ট্য কলাম (শ্রেণীবদ্ধ এবং সংখ্যাসূচক উভয়) গ্রহণ করবে এবং তাদের একক ভেক্টর কলামে একত্রিত করবে। স্পার্কের বেশিরভাগ মেশিন লার্নিং অ্যালগরিদমের জন্য এটি একটি প্রয়োজনীয়তা।
ট্রেন, পরীক্ষা = df.randomSplit([0.7, 0.3], বীজ = 42) আমরা আমাদের ডেটা একটি প্রশিক্ষণ সেট এবং একটি পরীক্ষার সেটে বিভক্ত করি, প্রশিক্ষণের জন্য 70% ডেটা এবং পরীক্ষার জন্য বাকি 30%।
lr = LogisticRegression (featuresCol="features", labelCol="label", maxIter=10)
lrModel = lr.fit(ট্রেন) আমরা আমাদের প্রশিক্ষণের ডেটাতে একটি লজিস্টিক রিগ্রেশন মডেল প্রশিক্ষণ দিই।
ভবিষ্যদ্বাণী = lrModel.transform(test)
predictions.select("customerID", "label", "prediction").show(5)
ভবিষ্যদ্বাণী.সিলেক্ট ("গ্রাহকআইডি", "লেবেল", "ভবিষ্যদ্বাণী").রাইট.অপশন ("শিরোনাম", "সত্য") \
.csv('s3a://ilum-files/predictions') পরিশেষে, আমরা আমাদের পরীক্ষার সেটে ভবিষ্যদ্বাণী করতে আমাদের প্রশিক্ষিত মডেলটি ব্যবহার করি, প্রথম 5 টি ভবিষ্যদ্বাণী প্রদর্শন করি। তারপরে আমরা এই ভবিষ্যদ্বাণীগুলি আমাদের মিনিও বালতিতে লিখি।
এই স্ক্রিপ্টটি এভাবে সংরক্ষণ করুন ilum_python_advanced.py
pyspark.ml নির্ভরতা হিসাবে নম্পি ব্যবহার করে যা ডিফল্ট হিসাবে ইনস্টল করা হয় না তাই আমাদের এটি একটি প্রয়োজনীয়তা হিসাবে নির্দিষ্ট করতে হবে।
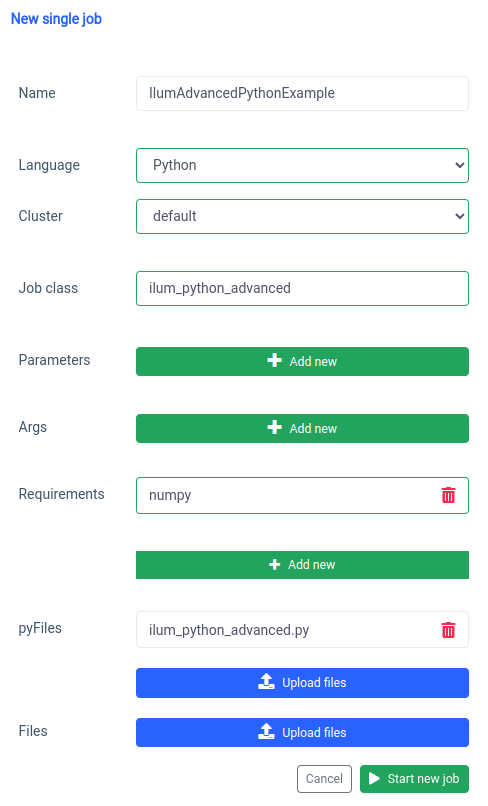
আর একই কাজ এপিআই এর মাধ্যমেও করা যায়।
কার্ল -এক্স পোস্ট 'লোকালহোস্ট: 9888 / এপিআই / ভি 1 / জব / সাবমিট' \
--ফর্ম 'name="IlumAdvancedPythonExample"' \
--ফর্ম 'ক্লাস্টারনাম="ডিফল্ট"' \
--ফর্ম 'জবক্লাস = "ilum_python_advanced"' \
--ফর্ম 'pyRequirements="numpy"' \
--ফর্ম 'pyFiles=@"/path/to/ilum_python_advanced.py"' \
--ফর্ম 'ভাষা="পাইথন"' এপিআই কল
পরবর্তী বিভাগগুলিতে, আমরা উভয় পাইথন স্ক্রিপ্টকে একটি রূপান্তর করব মিথষ্ক্রিয়ভাবে ইলুমের সামর্থ্যের পুরো সদ্ব্যবহার করে কাজ স্পার্ক করুন।
পদক্ষেপ 2: ইন্টারেক্টিভ মোডে রূপান্তর
ইন্টারেক্টিভ মোড একটি উত্তেজনাপূর্ণ বৈশিষ্ট্য যা স্পার্ক বিকাশকে আরও গতিশীল করে তোলে, আপনাকে রিয়েল টাইমে আপনার স্পার্ক কাজগুলি চালানোর, ইন্টারঅ্যাক্ট করার এবং নিয়ন্ত্রণ করার ক্ষমতা দেয়। এটি তাদের জন্য ডিজাইন করা হয়েছে যারা তাদের স্পার্ক অ্যাপ্লিকেশনগুলির উপর আরও সরাসরি নিয়ন্ত্রণ চান।
ইন্টারেক্টিভ মোডকে আপনার স্পার্ক কাজের সাথে সরাসরি কথোপকথন হিসাবে ভাবেন। আপনি ডেটাতে ফিড করতে পারেন, রূপান্তরগুলির জন্য অনুরোধ করতে পারেন এবং ফলাফলগুলি আনতে পারেন - সমস্ত রিয়েল টাইমে। এটি আপনার ডেটা প্রসেসিং পাইপলাইনের তত্পরতা এবং সক্ষমতা মারাত্মকভাবে বাড়ায়, এটি পরিবর্তিত প্রয়োজনীয়তার জন্য আরও অভিযোজিত এবং প্রতিক্রিয়াশীল করে তোলে।
এখন যেহেতু আমরা পাইথনে একটি বেসিক স্পার্ক জব তৈরির সাথে পরিচিত, আসুন আমাদের কাজটিকে একটি ইন্টারেক্টিভ একটিতে রূপান্তরিত করে জিনিসগুলিকে আরও এক ধাপ এগিয়ে নিয়ে যাই যা ইলুমের রিয়েল-টাইম ক্ষমতার সুবিধা নিতে পারে।
২.১ স্পার্কপাই উদাহরণ।
কীভাবে আমাদের কাজটি ইন্টারেক্টিভ মোডে স্থানান্তর করা যায় তা ব্যাখ্যা করার জন্য, আমরা আমাদের পূর্বের সামঞ্জস্য করব ilum_python_simple.py লিপি।
এলোমেলো আমদানি থেকে এলোমেলো
অপারেটর থেকে আমদানি যোগ করুন
ilum.api আমদানি IlumJob থেকে
ক্লাস স্পার্কপাইইন্টারেক্টিভউদাহরণ (ইলুমজব):
ডিএফ রান (স্ব, স্পার্ক, কনফিগ):
পার্টিশন = int(config.get('partitions', '5'))
n = 100000* পার্টিশন
def f(_: int) -> float:
x = random() * 2 - 1
y = random() * 2 - 1
রিটার্ন 1 যদি এক্স ** 2 + ওয়াই ** 2 < = 1 অন্য 0
গণনা = স্পার্ক.স্পার্ককনটেক্সট.সমান্তরালকরণ (পরিসীমা (1, এন + 1), পার্টিশন).map(f).reduce(add)
রিটার্ন "পাই মোটামুটি %f"% (4.0 * গণনা / এন) এটি এভাবে সংরক্ষণ করুন ilum_python_simple_interactive.py
মূল স্পার্কপাই থেকে কয়েকটি পার্থক্য রয়েছে।
1. Ilum প্যাকেজ
শুরু করার জন্য, আমরা আমদানি করি ইলুমজব আইএলইউএম প্যাকেজ থেকে ক্লাস, যা আমাদের ইন্টারেক্টিভ কাজের জন্য বেস ক্লাস হিসাবে কাজ করে।
স্পার্ক কাজের যুক্তিটি এমন একটি শ্রেণিতে আবদ্ধ যা প্রসারিত হয় ইলুমজব , বিশেষ করে এর মধ্যে চালনা পদ্ধতি। আমরা এর সাথে ইলাম প্যাকেজ যুক্ত করতে পারি:
পিপ ইনস্টল ইলুম 2. একটি ক্লাসে স্পার্ক চাকরি
স্পার্ক কাজের যুক্তিটি এমন একটি শ্রেণিতে আবদ্ধ যা প্রসারিত হয় ইলুমজব , বিশেষ করে এর মধ্যে চালনা পদ্ধতি।
ক্লাস স্পার্কপাইইন্টারেক্টিভউদাহরণ (ইলুমজব):
ডিএফ রান (স্ব, স্পার্ক, কনফিগ):
# এখানে চাকরির যুক্তি চাকরি এবং এর সংস্থানগুলি পরিচালনা করার জন্য ইলুম কাঠামোর জন্য একটি ক্লাসে কাজের যুক্তি মোড়ানো অপরিহার্য। এটি কাজটিকে রাষ্ট্রহীন এবং পুনরায় ব্যবহারযোগ্য করে তোলে।
3. পরামিতি ভিন্নভাবে পরিচালনা করা হয়:
আমরা কনফিগ অভিধান থেকে সমস্ত আর্গুমেন্ট নিচ্ছি
পার্টিশন = int(config.get('partitions', '5')) এই শিফটটি আরও গতিশীল প্যারামিটার পাসের অনুমতি দেয় এবং ইলুমের কনফিগারেশন হ্যান্ডলিংয়ের সাথে সংহত করে।
4. ফলাফল মুদ্রণের পরিবর্তে ফেরত দেওয়া হয়:
ফলাফল থেকে ফিরে আসে চালনা পদ্ধতি।
রিটার্ন "পাই মোটামুটি %f"% (4.0 * গণনা / এন) ফলাফলটি ফিরিয়ে দিয়ে, ইলাম এটি আরও নমনীয় উপায়ে পরিচালনা করতে পারে। উদাহরণস্বরূপ, ইলাম ফলাফলটি সিরিয়ালাইজ করতে পারে এবং এটি একটি এপিআই কলের মাধ্যমে অ্যাক্সেসযোগ্য করে তুলতে পারে।
5. স্পার্ক সেশন ম্যানুয়ালি পরিচালনা করার দরকার নেই
ইলাম আমাদের জন্য স্পার্ক সেশন পরিচালনা করে। এটি স্বয়ংক্রিয়ভাবে ইনজেকশনের মধ্যে প্রবেশ করানো হয় চালনা পদ্ধতি এবং আমাদের এটি ম্যানুয়ালি বন্ধ করার দরকার নেই।
ডিএফ রান (স্ব, স্পার্ক, কনফিগ): এই পরিবর্তনগুলি একটি স্বতন্ত্র স্পার্ক কাজ থেকে একটি ইন্টারেক্টিভ ইলম চাকরিতে রূপান্তরকে হাইলাইট করে। লক্ষ্যটি হ'ল কাজের নমনীয়তা এবং পুনরায় ব্যবহারযোগ্যতা উন্নত করা, এটি গতিশীল, ইন্টারেক্টিভ এবং অন-দ্য-ফ্লাই গণনার জন্য আরও উপযুক্ত করে তোলে।
ইন্টারেক্টিভ স্পার্ক কাজ যুক্ত করা 'নতুন গোষ্ঠী' ফাংশনের সাথে পরিচালিত হয়।
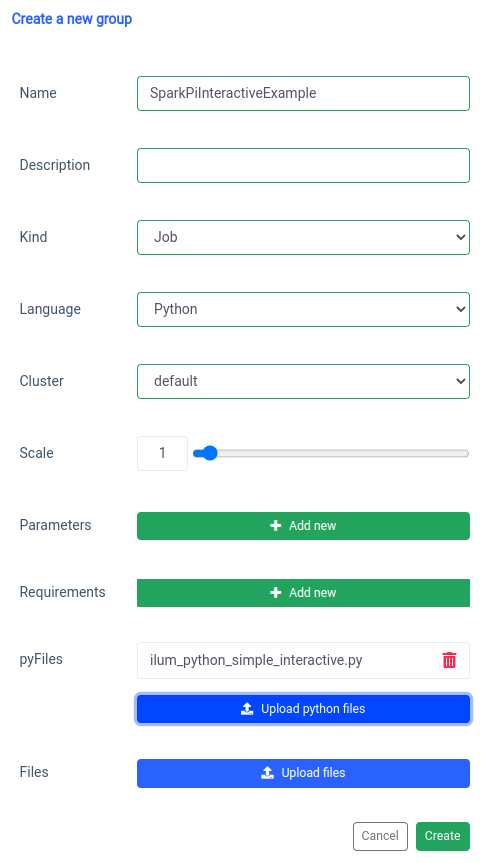
এবং ইউআইতে ইন্টারেক্টিভ জব ফাংশন সহ এক্সিকিউশন।
শ্রেণীর নাম একটি হিসাবে নির্দিষ্ট করা উচিত pythonFileName.PythonClassImplementingIlumJob
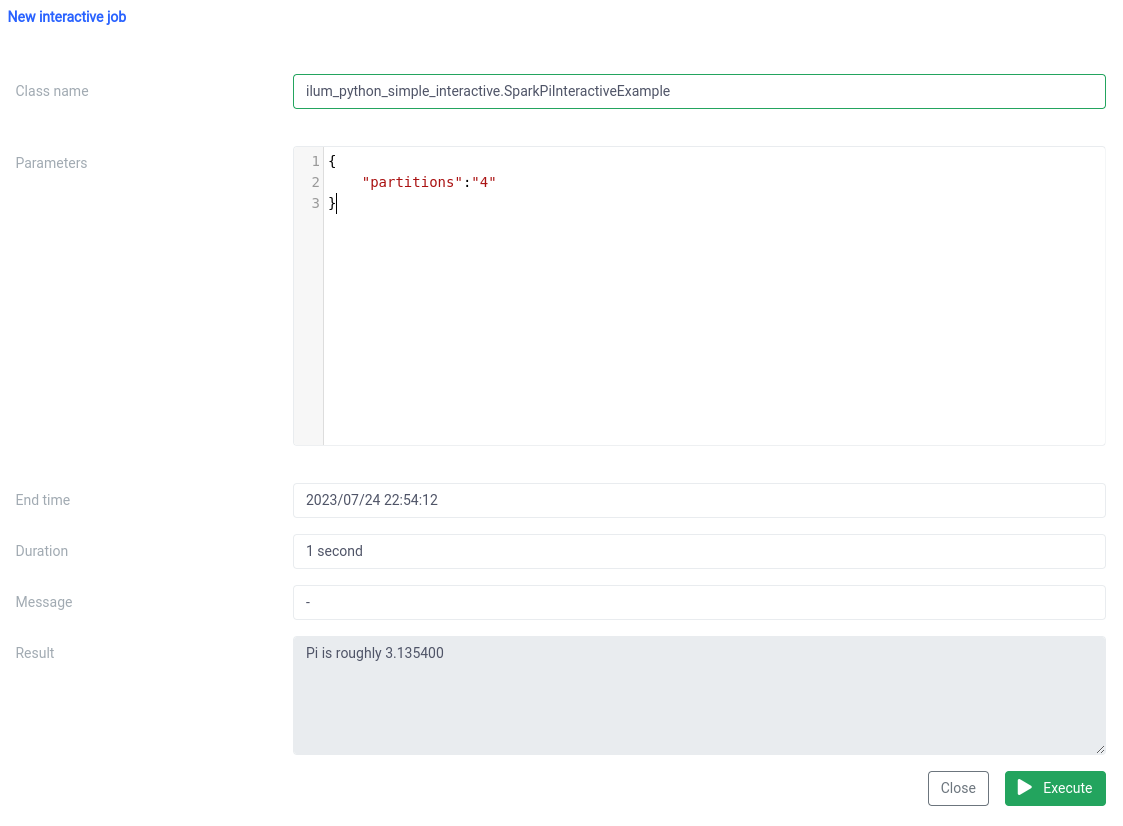
আমরা একই জিনিস সঙ্গে অর্জন করতে পারেন এপিআই .
১. গ্রুপ তৈরি করা
কার্ল -এক্স পোস্ট 'লোকালহোস্ট: 9888 / এপিআই / ভি 1 / গ্রুপ' \
--ফর্ম 'name="SparkPiInteractiveExample"' \
--ফর্ম 'কাইন্ড="জব"' \
--ফর্ম 'ক্লাস্টারনাম="ডিফল্ট"' \
--ফর্ম 'pyFiles=@"/path/to/ilum_python_simple_interactive.py"' \
--ফর্ম 'ভাষা="পাইথন"' এপিআই কল
{"groupId":"20230726-1638-mjrw3"} ফলাফল
২. জব এক্সিকিউশন
কার্ল -এক্স পোস্ট 'localhost:9888/api/v1/group/20230726-1638-mjrw3/job/execute' \
-এইচ 'সামগ্রী-প্রকার: অ্যাপ্লিকেশন / জেসন' \
-ডি '{ "জবক্লাস":"ilum_python_simple_interactive। SparkPiInteractiveExample", "jobConfig": {"partitions":"10"}, "type":"interactive_job_execute"}' এপিআই কল
{
"jobInstanceId":"20230726-1638-mjrw3-a1srahhu",
"jobId":"20230726-1638-mjrw3-wwt5a",
"groupId":"20230726-1638-mjrw3",
"স্টার্টটাইম":1690390323154,
"এন্ডটাইম":1690390325200,
"জবক্লাস":"ilum_python_simple_interactive। স্পার্কপাইইন্টারেক্টিভ উদাহরণ",
"jobConfig":{
"পার্টিশন":"10"
},
"ফলাফল":"পাই মোটামুটি 3.149400",
"ত্রুটি":নাল
} ফলাফল
2.2 অসাড় সঙ্গে কাজের উদাহরণ।
আমাদের দ্বিতীয় উদাহরণটি দেখা যাক।
pyspark.sql থেকে স্পার্কসেশন আমদানি করুন
pyspark.ml আমদানি পাইপলাইন থেকে
pyspark.ml.feature আমদানি StringIndexer, VectorAssembler থেকে
pyspark.ml.classification আমদানি থেকে লজিস্টিক রিগ্রেশন
ilum.api আমদানি IlumJob থেকে
ক্লাস লজিস্টিক রিগ্রেশনজবউদাহরণ (ইলুমজব):
ডিএফ রান (স্ব, spark_session: স্পার্কসেশন, কনফিগারেশন: ডিক্ট) -> স্ট্র:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True,
ইনফারস্কিমা = সত্য)
categoricalColumns = ['লিঙ্গ', 'অংশীদার', 'নির্ভরশীল', 'ফোন পরিষেবা', 'মাল্টিপললাইন', 'ইন্টারনেট সার্ভিস',
'অনলাইনসিকিউরিটি', 'অনলাইনব্যাকআপ', 'ডিভাইসপ্রোটেকশন', 'টেকসাপোর্ট', 'স্ট্রিমিংটিভি',
'স্ট্রিমিংমুভিজ', 'কন্ট্রাক্ট', 'পেপারলেস বিলিং', 'পেমেন্ট মেথড']
পর্যায় = []
ক্যাটাগরিকাল কলামগুলিতে ক্যাটাগরিকাল কলের জন্য:
stringIndexer = StringIndexer (inputCol=categoricalCol, outputCol=categoricalCol + "index")
পর্যায় += [stringIndexer]
label_stringIdx = StringIndexer (inputCol="Churn", outputCol="label")
পর্যায় += [label_stringIdx]
সংখ্যাসূচক = ['সিনিয়র সিটিজেন', 'মেয়াদ', 'মাসিক চার্জ']
অ্যাসেম্বলারইনপুটস = [সি + "সূচক" শ্রেণীবদ্ধ কলামগুলিতে সি এর জন্য] + সংখ্যাসূচক
অ্যাসেম্বলার = ভেক্টরঅ্যাসেম্বলার (inputCols=assemblerInputs, outputCol="features")
পর্যায় += [অ্যাসেম্বলার]
পাইপলাইন = পাইপলাইন (পর্যায় = পর্যায়)
পাইপলাইনমডেল = পাইপলাইন.ফিট (ডিএফ)
ডিএফ = পাইপলাইনমডেল.ট্রান্সফর্ম (ডিএফ)
ট্রেন, পরীক্ষা = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))],
বীজ = আইএনটি (কনফিগ.গেট ('বীজ', '42')))
lr = LogisticRegression (featuresCol="features", labelCol="label", maxIter=int(config.get('maxIter', '5')))
lrModel = lr.fit(ট্রেন)
ভবিষ্যদ্বাণী = lrModel.transform(test)
return '{}'.format(predictions.select("customerID", "label", "prediction").limit(
int(config.get('rowLimit', '5')).toJSON().collect()) 1. আমরা পূর্ববর্তী উদাহরণের মতো একটি ক্লাসে কাজটি মোড়াই:
ক্লাস লজিস্টিক রিগ্রেশনজবউদাহরণ (ইলুমজব):
ডিএফ রান (স্ব, spark_session: স্পার্কসেশন, কনফিগারেশন: ডিক্ট) -> স্ট্র:
# এখানে চাকরির যুক্তি আবার, কাজের যুক্তিটি এনক্যাপসুলেট করা হয়েছে চালনা ক্লাস সম্প্রসারণের পদ্ধতি ইলুমজব , ইলুমকে দক্ষতার সাথে কাজটি পরিচালনা করতে সহায়তা করে।
2. ডেটা পাইপলাইনের জন্য (যেমন ফাইল পাথ এবং লজিস্টিক রিগ্রেশন হাইপারপ্যারামিটার) সহ সমস্ত পরামিতি থেকে প্রাপ্ত হয় কনফিগার অভিধান:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True, inferSchema=True)
ট্রেন, টেস্ট = ডিএফ.র্যান্ডমস্প্লিট ([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))], seed=int(config.get('বীজ', '42')))
lr = LogisticRegression (featuresCol="features", labelCol="label", maxIter=int(config.get('maxIter', '5'))) সমস্ত পরামিতিগুলিকে এক জায়গায় কেন্দ্রীভূত করে, ইলাম কাজটি কনফিগার এবং টিউন করার একটি অভিন্ন, সামঞ্জস্যপূর্ণ উপায় সরবরাহ করে।
কাজের ফলাফল, একটি নির্দিষ্ট স্থানে লেখা হওয়ার পরিবর্তে, একটি জেএসওএন স্ট্রিং হিসাবে ফিরে আসে:
return '{}'.format(predictions.select("customerID", "label", "prediction").limit(int(config.get('rowLimit', '5')).toJSON().collect()) এটি কাজের ফলাফলের আরও গতিশীল এবং নমনীয় হ্যান্ডলিংয়ের অনুমতি দেয়, যা অ্যাপ্লিকেশনটির প্রয়োজনের উপর নির্ভর করে আরও প্রক্রিয়া করা যেতে পারে বা এপিআইয়ের মাধ্যমে প্রকাশ করা যেতে পারে।
এই কোডটি পুরোপুরি দেখায় যে আমরা কীভাবে ইন্টারেক্টিভ, এপিআই-চালিত ডেটা প্রসেসিং পাইপলাইনগুলি সক্ষম করতে ইলুমের সাথে পাইস্পার্ক কাজগুলিকে নির্বিঘ্নে সংহত করতে পারি। পাই আনুমানিকতার মতো সাধারণ উদাহরণ থেকে লজিস্টিক রিগ্রেশনের মতো আরও জটিল ক্ষেত্রে ইলামের ইন্টারেক্টিভ কাজগুলি বহুমুখী, অভিযোজনযোগ্য এবং দক্ষ।
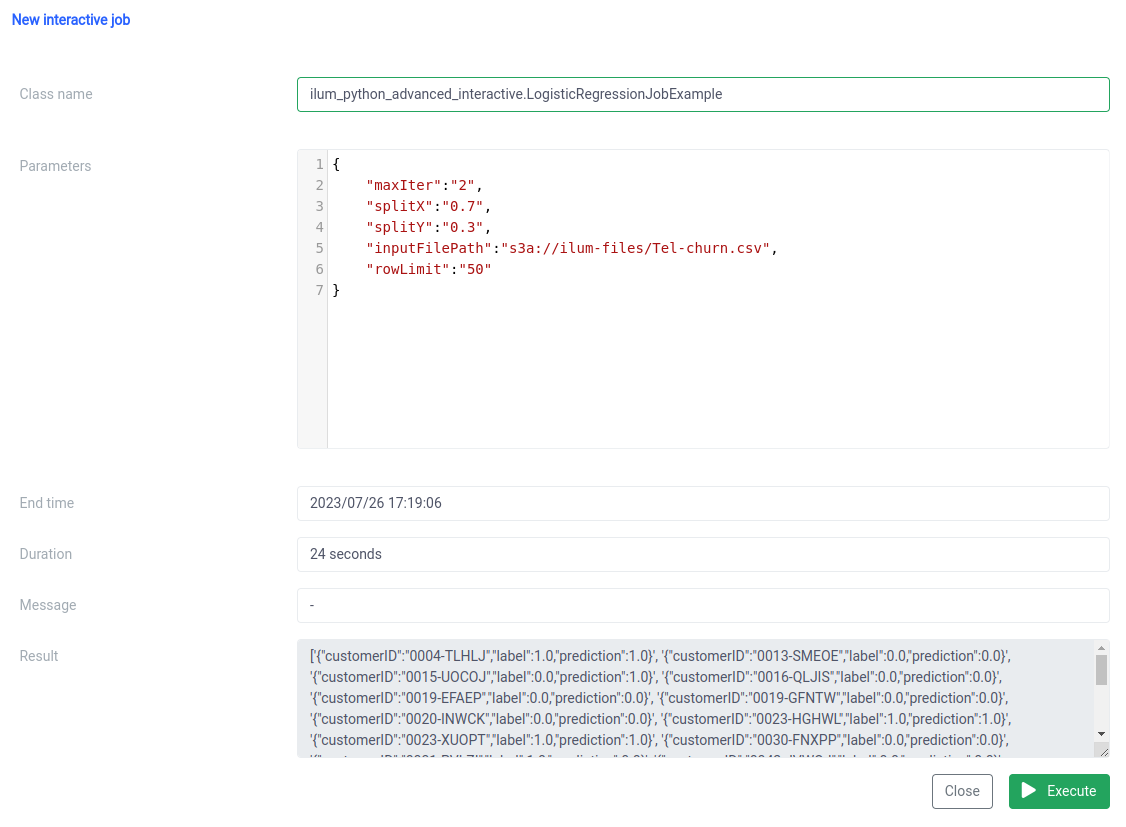
পদক্ষেপ 3: আপনার স্পার্ক কাজকে একটি মাইক্রোসার্ভিস তৈরি করা
মাইক্রোসার্ভিসেস ঐতিহ্যবাহী একচেটিয়া অ্যাপ্লিকেশন কাঠামো থেকে আরও মডুলার এবং চটপটে পদ্ধতির দিকে একটি দৃষ্টান্ত পরিবর্তন নিয়ে আসে। একটি জটিল অ্যাপ্লিকেশনকে ছোট, আলগাভাবে সংযুক্ত পরিষেবাগুলিতে বিভক্ত করে, নির্দিষ্ট প্রয়োজনীয়তার উপর ভিত্তি করে প্রতিটি পরিষেবা স্বাধীনভাবে তৈরি, রক্ষণাবেক্ষণ এবং স্কেল করা সহজ হয়ে যায়। আমাদের স্পার্ক কাজের জন্য প্রয়োগ করা হলে, এর অর্থ আমরা একটি শক্তিশালী ডেটা প্রসেসিং পরিষেবা তৈরি করতে পারি যা আমাদের অ্যাপ্লিকেশন স্ট্যাকের অন্যান্য অংশগুলিকে প্রভাবিত না করেই স্কেল, পরিচালনা এবং আপডেট করা যেতে পারে।
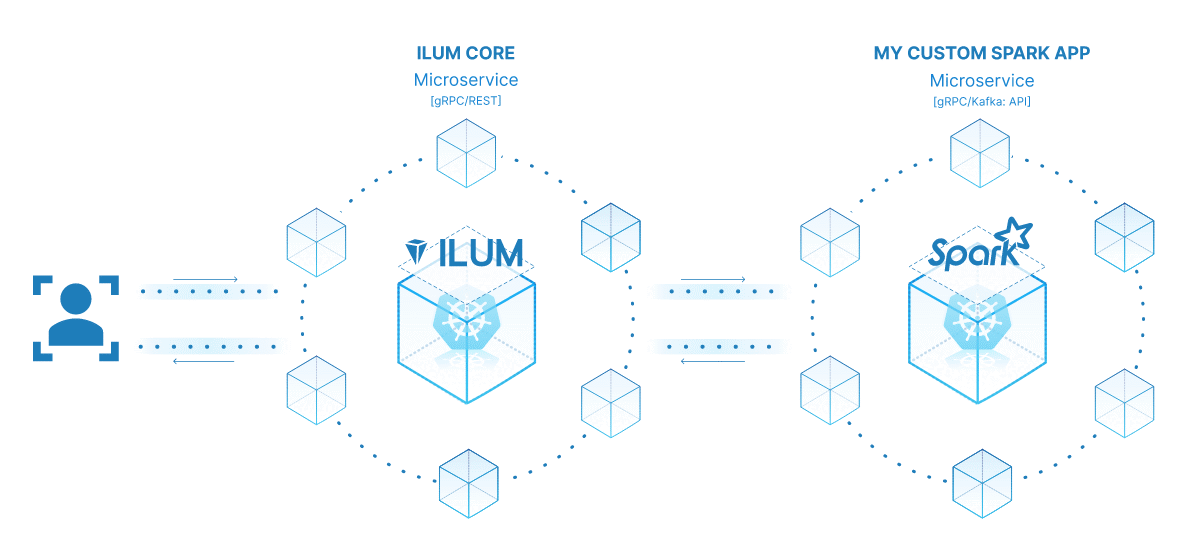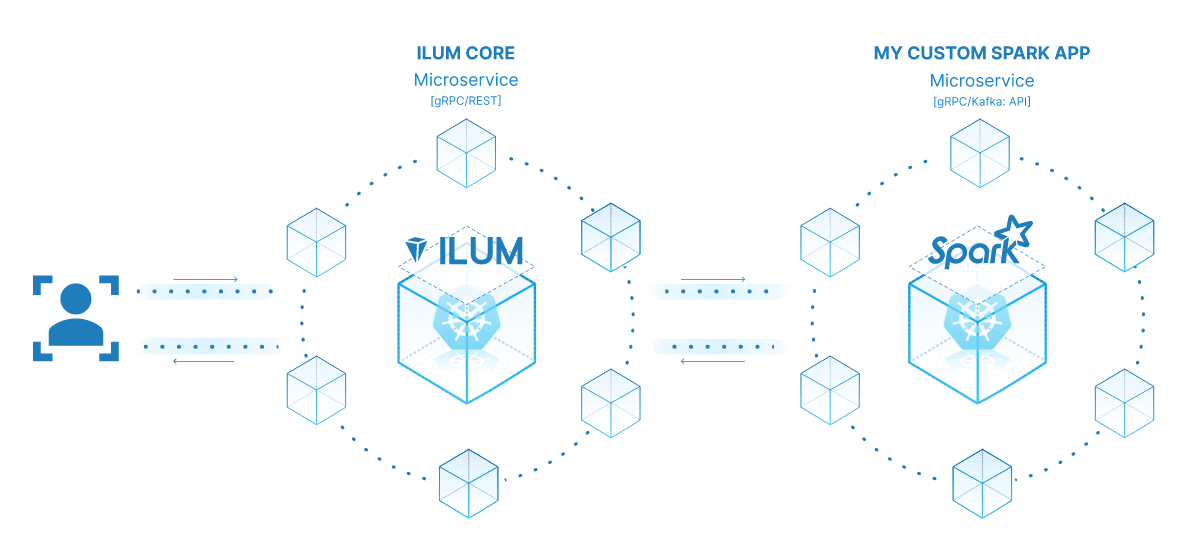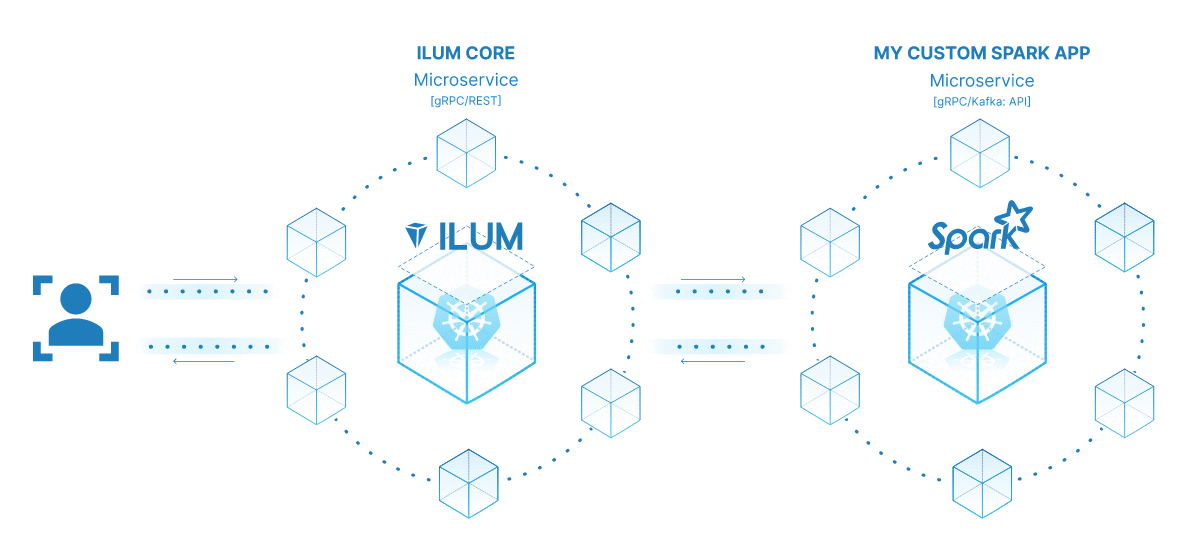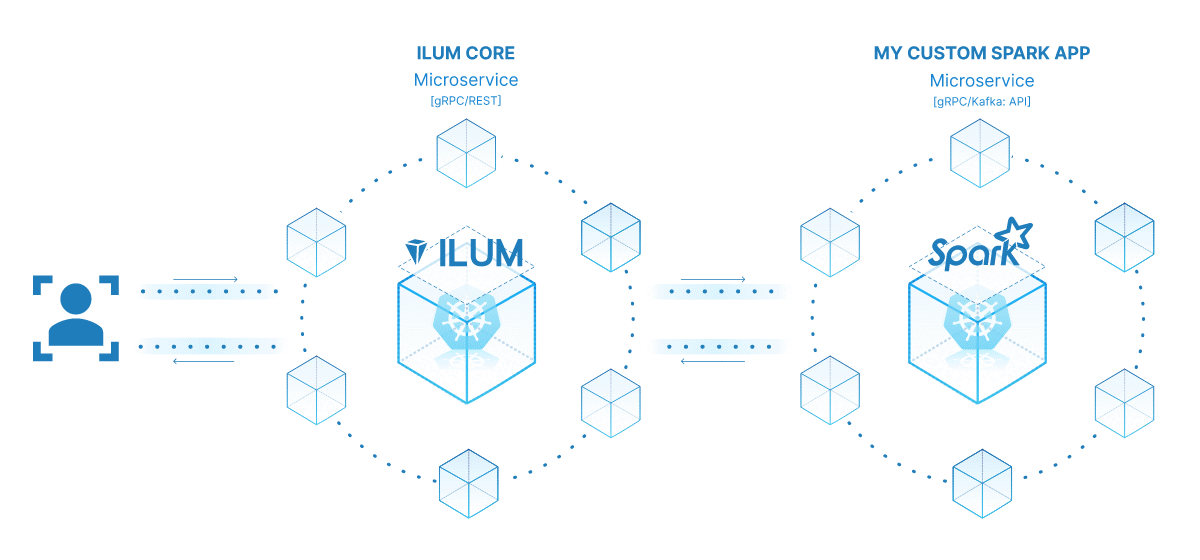
আপনার স্পার্ক কাজটিকে মাইক্রোসার্ভিসে পরিণত করার শক্তি এর বহুমুখিতা, স্কেলেবিলিটি এবং রিয়েল-টাইম ইন্টারঅ্যাকশন ক্ষমতার মধ্যে রয়েছে। একটি মাইক্রোসার্ভিস একটি অ্যাপ্লিকেশনের একটি স্বাধীনভাবে মোতায়েনযোগ্য উপাদান যা একটি পৃথক প্রক্রিয়া হিসাবে চলে। এটি সু-সংজ্ঞায়িত এপিআইগুলির মাধ্যমে অন্যান্য উপাদানগুলির সাথে যোগাযোগ করে, আপনাকে প্রতিটি মাইক্রোসার্ভিস স্বাধীনভাবে ডিজাইন, বিকাশ, স্থাপন এবং স্কেল করার স্বাধীনতা দেয়।
ইলুমের প্রসঙ্গে, একটি ইন্টারেক্টিভ স্পার্ক কাজকে মাইক্রোসার্ভিস হিসাবে বিবেচনা করা যেতে পারে। কাজের 'রান' পদ্ধতিটি এপিআই এন্ডপয়েন্ট হিসাবে কাজ করে। আপনি যখনই ইলুমের এপিআইয়ের মাধ্যমে এই পদ্ধতিটি কল করেন, আপনি এই মাইক্রোসার্ভিসের কাছে একটি অনুরোধ করছেন। এটি আপনার স্পার্ক কাজের সাথে রিয়েল-টাইম ইন্টারঅ্যাকশনের সম্ভাবনা উন্মুক্ত করে।
আপনি বিভিন্ন অ্যাপ্লিকেশন বা স্ক্রিপ্ট থেকে আপনার মাইক্রোসার্ভিসে অনুরোধ করতে পারেন, ডেটা আনতে পারেন এবং ফ্লাইতে ফলাফল প্রক্রিয়াকরণ করতে পারেন। তদুপরি, এটি আপনার ডেটা প্রসেসিং পাইপলাইনগুলির চারপাশে আরও জটিল, পরিষেবা-ভিত্তিক আর্কিটেকচার তৈরির সুযোগ উন্মুক্ত করে।
এই সেটআপের একটি মূল সুবিধা হ'ল স্কেলাবিলিটি। ইলাম ইউআই বা এপিআইয়ের মাধ্যমে, আপনি লোড বা গণনামূলক জটিলতার উপর ভিত্তি করে আপনার কাজ (মাইক্রোসার্ভিস) উপরে বা নীচে স্কেল করতে পারেন। আপনাকে ম্যানুয়ালি সংস্থানগুলি পরিচালনা বা লোড ভারসাম্য সম্পর্কে চিন্তা করার দরকার নেই। ইলামের অভ্যন্তরীণ লোড ব্যালেন্সার আপনার স্পার্ক কাজের উদাহরণগুলির মধ্যে এপিআই কল বিতরণ করবে, দক্ষ সংস্থান ব্যবহার নিশ্চিত করবে।
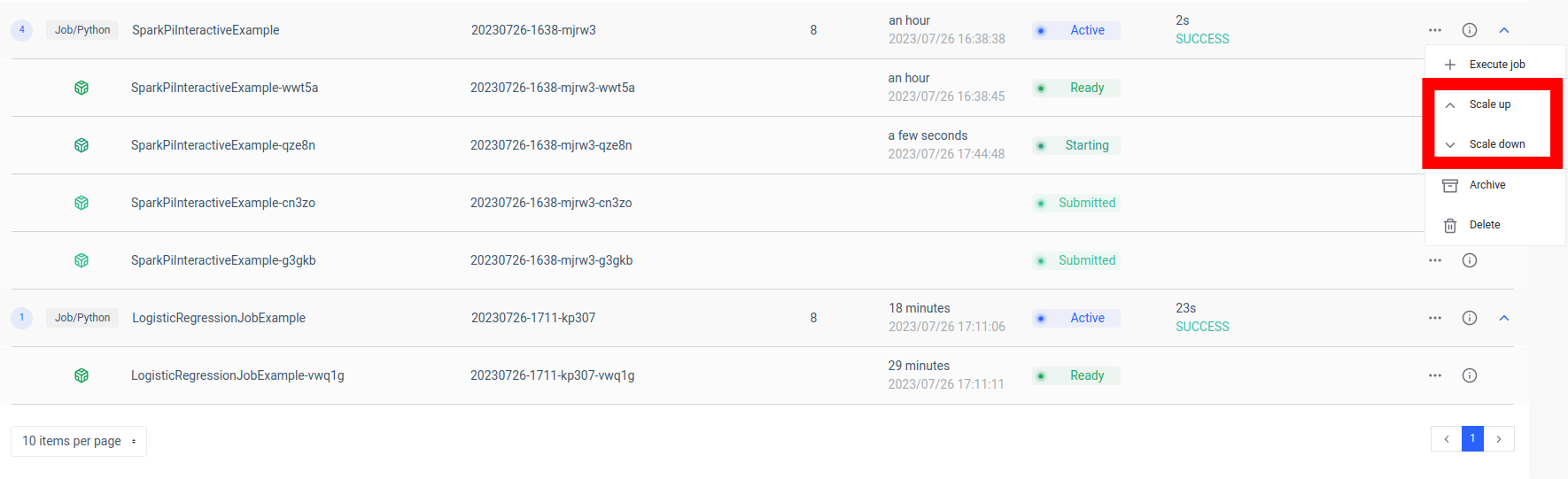
মনে রাখবেন যে কাজের প্রকৃত প্রক্রিয়াকরণের সময়টি স্পার্ক কাজের জটিলতা এবং এতে বরাদ্দ করা সংস্থানগুলির উপর নির্ভর করে। তবে, কুবারনেটস দ্বারা প্রদত্ত স্কেলেবিলিটির সাহায্যে আপনার কাজের প্রয়োজনীয়তা বাড়ার সাথে সাথে আপনি সহজেই আপনার সংস্থানগুলি স্কেল করতে পারেন।
ইলাম, অ্যাপাচি স্পার্ক এবং মাইক্রোসার্ভিসেসের এই সংমিশ্রণটি আপনার ডেটা প্রক্রিয়া করার জন্য একটি নতুন, চটপটে উপায় নিয়ে আসে - দক্ষতা, স্কেলযোগ্য এবং প্রতিক্রিয়াশীলভাবে!

ডেটা মাইক্রোসার্ভিস আর্কিটেকচারে গেম-চেঞ্জার
আমরা ইলাম ব্যবহার করে একটি সাধারণ পাইথন অ্যাপাচি স্পার্ক কাজকে একটি পূর্ণাঙ্গ মাইক্রোসার্ভিসে রূপান্তরিত করার এই যাত্রা শুরু করার পর থেকে আমরা অনেক দূর এগিয়েছি। আমরা দেখেছি যে একটি স্পার্ক কাজ লেখা, ইন্টারেক্টিভ মোডে কাজ করার জন্য এটি অভিযোজিত করা এবং শেষ পর্যন্ত ইলামের শক্তিশালী এপিআইয়ের সাহায্যে এটি একটি মাইক্রোসার্ভিস হিসাবে প্রকাশ করা কতটা সহজ ছিল। পথে, আমরা পাইথনের শক্তি, অ্যাপাচি স্পার্কের ক্ষমতা এবং ইলুমের নমনীয়তা এবং স্কেলেবিলিটি লাভ করেছি। এই সংমিশ্রণটি কেবল আমাদের ডেটা প্রসেসিং ক্ষমতাকেই রূপান্তরিত করেনি তবে ডেটা আর্কিটেকচার সম্পর্কে আমাদের চিন্তাভাবনাও পরিবর্তন করেছে।
যাত্রা এখানেই থেমে নেই। আইলুমে সম্পূর্ণ পাইথন সমর্থন সহ, ডেটা প্রসেসিং এবং বিশ্লেষণের জন্য সম্ভাবনার একটি নতুন বিশ্ব উন্মুক্ত হয়। যেহেতু আমরা ইলুমে নির্মাণ এবং উন্নতি অব্যাহত রেখেছি, পাইথন আমাদের প্ল্যাটফর্মে যে ভবিষ্যতের সম্ভাবনা নিয়ে আসে তা নিয়ে আমরা উত্তেজিত। আমরা বিশ্বাস করি যে পাইথন এবং ইলুম একসাথে থাকায়, আমরা ডেটা মাইক্রোসার্ভিস আর্কিটেকচারের বিশ্বে কী সম্ভব তা পুনরায় সংজ্ঞায়িত করার শুরুতে রয়েছি।
এই উত্তেজনাপূর্ণ যাত্রায় আমাদের সাথে যোগ দিন, এবং আসুন একসাথে ডেটা প্রসেসিংয়ের ভবিষ্যতকে আকার দিই!